Spark内核源码深度剖析
Spark内核架构深度剖析

Spark内核架构
1 | |
宽依赖与窄依赖深度剖析

基于Yarn的两种提交模式深度剖析
Spark的三种提交模式
1 | |
基于YARN的两种提交模式深度剖析:

1 | |
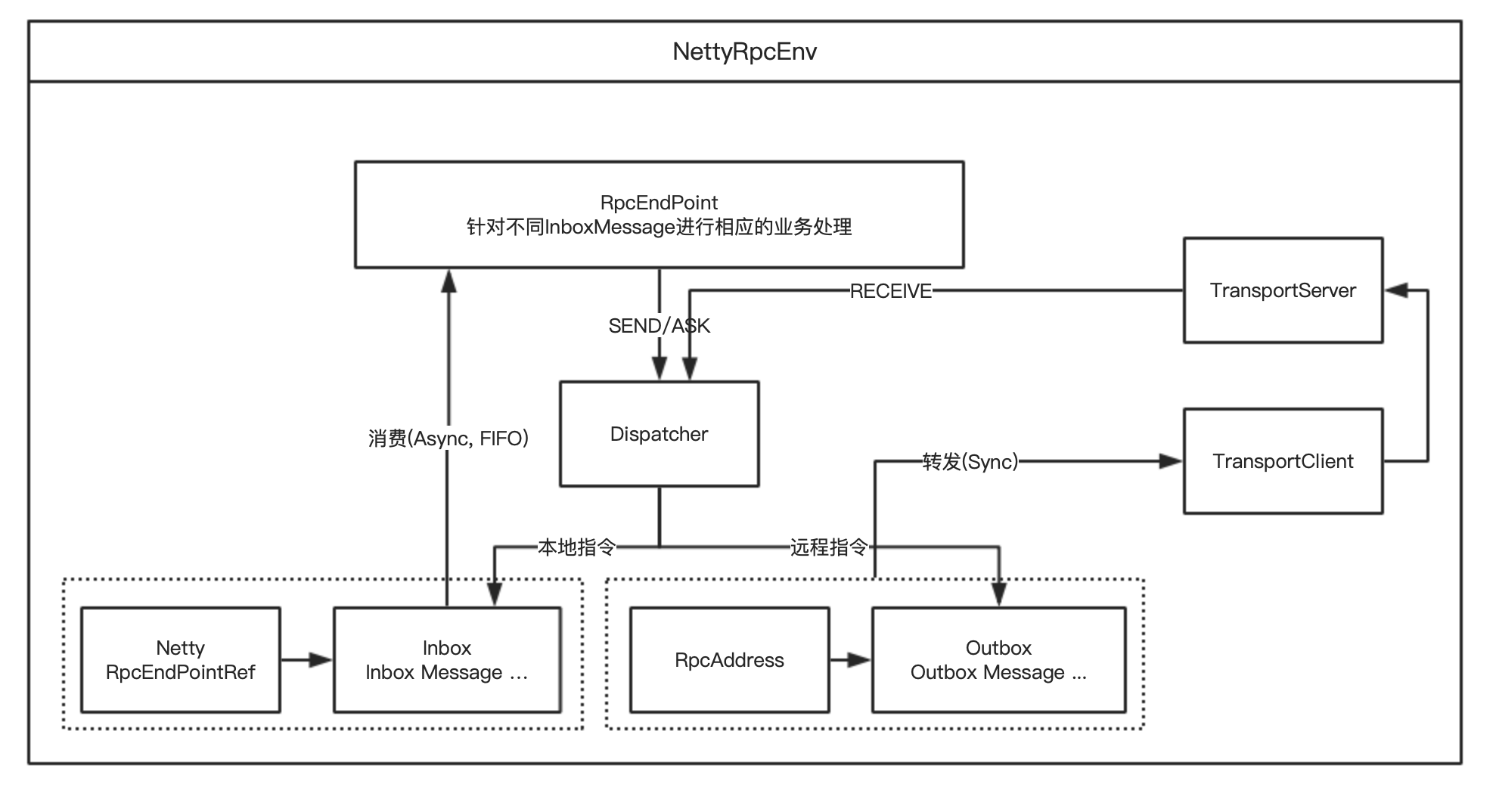
Spark 通信架构
Spark2.X版本使用Netty框架作为内部通信组件,基于Netty新的RPC框架,基于Actor模型。
EndPoint (Client/Master/Worker) 有1个InBox和N个OutBox (N>=1, N取决于当前EndPoint与多少其他EndPoint通信)
1 | |
Spark通信框架,Driver与Executor通信过程如下图所示:
SparkContext原理剖析与源码分析
SparkContex原理剖析
1 | |

Master主备切换机制原理剖析与源码分析
Master原理剖析与源码分析
1 | |
主备切换机制原理剖析:

Master注册机制原理剖析与源码分析
1 | |

Master状态改变处理机制原理剖析与源码分析
1 | |
Master资源调度算法原理剖析与源码分析
1 | |
Worker原理剖析与源码分析
Worker原理剖析:

Job触发流程原理剖析与源码分析
wordcount
1 | |
其实RDD里是没有reduceByKey的,因此对RDD调用reduceByKey()方法的时候,会触发scala的隐式转换;此时就会在作用域内,寻找隐式转换,会在RDD中找到rddToPairRDDFunctions()隐式转换,然后将RDD转换为PairRDDFunctions。
接着会调用PairRDDFunctions中的reduceByKey()方法
1 | |
DAGScheduler原理剖析与源码分析
WordCount例子代码:
1 | |
stage划分算法原理剖析:

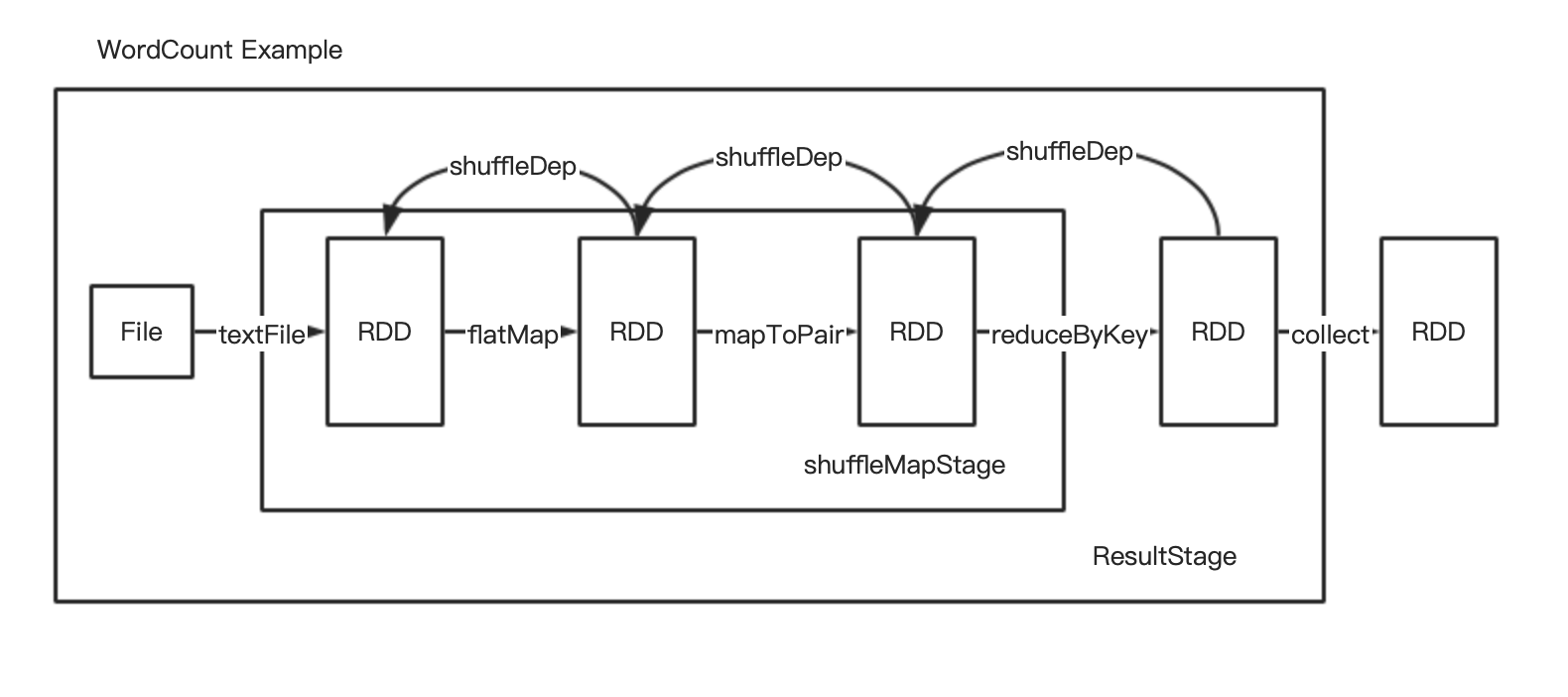
装饰者设计模式 RDD进过transform操作一层层包装
1 | |
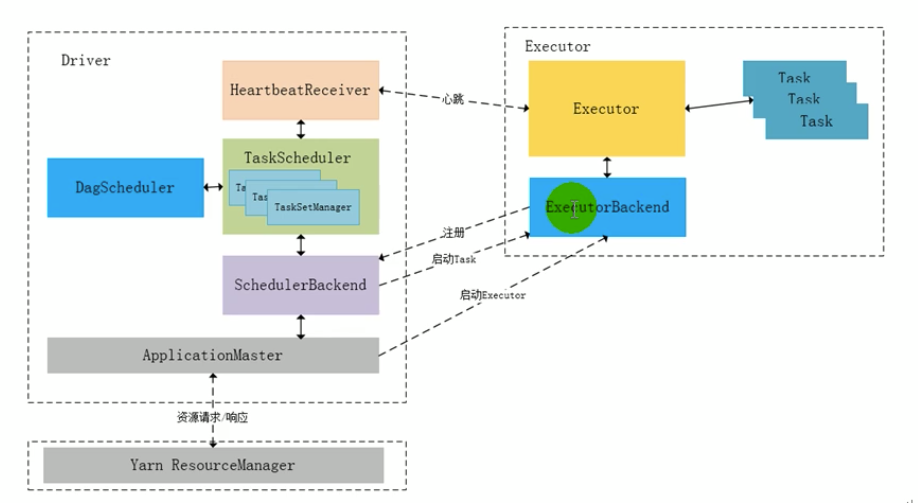
TaskScheduler原理剖析与源码分析
Executor原理剖析与源码分析
Executor原理剖析与源码分析
1 | |
Executor原理剖析:

Task原理剖析与源码分析
Task原理剖析:

Shuffle原理剖析与源码分析
Shuffle原理剖析
- 在Spark中reduceByKey, groupByKey, sortByKey, countByKey, join, cogroup等操作情况下,会发生shuffle
Shuffle源码分析
-
ShuffleMapStage 和 ResultStage
ShuffleMapStage结束伴随着shuffle文件写磁盘。ResultStage基本上对应着行动(action)算子,即将一个函数应用在RDD的各个partition数据集上,意味着一个job的运行结束
-
Shuffle中的任务个数
Shuffle分为map阶段(ShuffleMapStage)和reduce(ResultStage)阶段,或者称之为ShuffleRead和ShuffleWrite阶段。
如果文件中读取数据由split个数决定。
如果初始RDD经过一系列算子计算后(假设没有执行repartition和coalesce算子进行重新分区,则分区个数不变仍为N,如果经过重分区算子,分区个数变为M),那么执行到shuffle操作时,map端task个数与分区一致,即为N;reduce端stage默认取spark.default.parallelism这个配置项的值作为分区数,如果没有配置则以map端最后一个RDD分区数作为其分区数也就是N。
1 | |
-
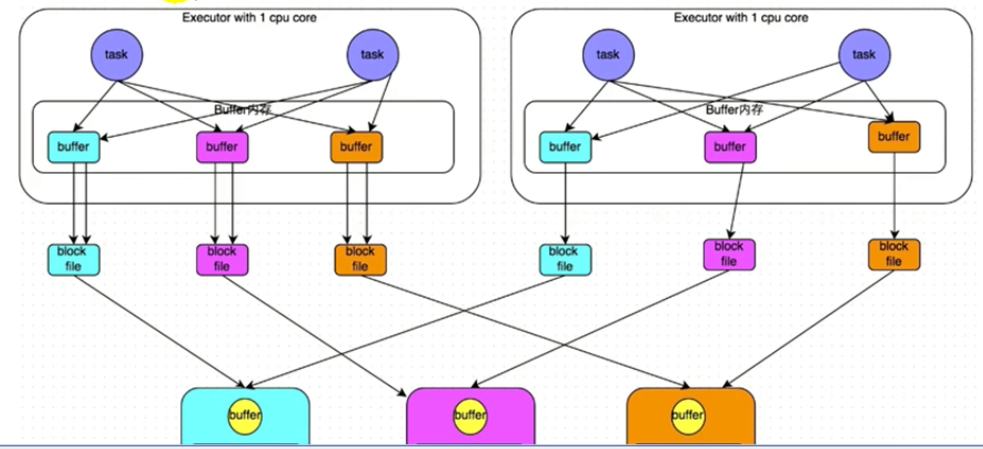
早期版本的HashShuffle操作的原理剖析
未经优化HashShuffleManager:M个map端task输出到N个reduce端task分别对应的文件,共产生M*N个文件。缺点小文件太多
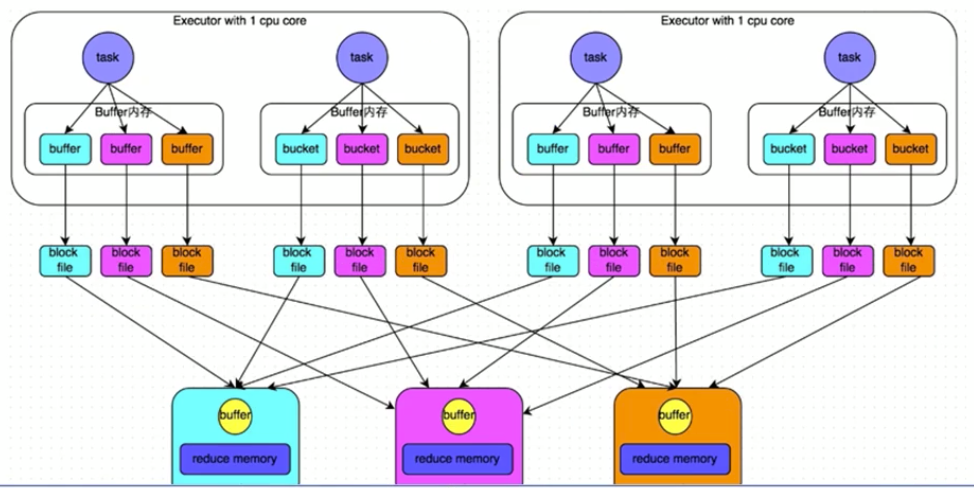
经优化HashShuffleManager:Executor 1 cpu core共用一个输出文件,M个map端task输出到N个reduce端task分别对应的文件,共产生NumberOfCore*N个文件。小文件有所减少,但是如果集群core多的话小文件还是多
-
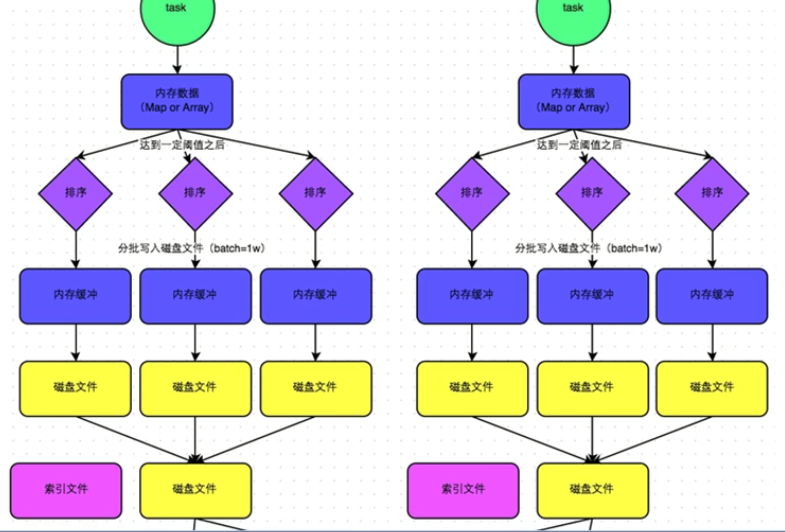
优化后的SortShuffle操作的原理剖析
SortShuffle:map端输出索引文件和磁盘文件
1 | |
Spark Shuffle操作的两个特点
第一个特点
在Spark早期版本中,那个bucket缓存是非常非常重要的,因为需要将一个ShuffleMapTask所有的数据都写入内存缓存之后,才会刷新到磁盘。但是这就有一个问题,如果map side数据过多,那么很容易造成内存溢出。所以spark在新版本中,优化了,默认那个内存缓存是100kb,然后呢,写入一点数据达到了刷新到磁盘的阈值之后,就会将数据一点一点地刷新到磁盘。
这种操作的优点,是不容易发生内存溢出。缺点在于,如果内存缓存过小的话,那么可能发生过多的磁盘写io操作。所以,这里的内存缓存大小,是可以根据实际的业务情况进行优化的。
第二个特点
与MapReduce完全不一样的是,MapReduce它必须将所有的数据都写入本地磁盘文件以后,才能启动reduce操作,来拉取数据。为什么?因为mapreduce要实现默认的根据key的排序!所以要排序,肯定得写完所有数据,才能排序,然后reduce来拉取。
但是Spark不需要,spark默认情况下,是不会对数据进行排序的。因此ShuffleMapTask每写入一点数据,ResultTask就可以拉取一点数据,然后在本地执行我们定义的聚合函数和算子,进行计算。
spark这种机制的好处在于,速度比mapreduce快多了。但是也有一个问题,mapreduce提供的reduce,是可以处理每个key对应的value上的,很方便。但是spark中,由于这种实时拉取的机制,因此提供不了,直接处理key对应的values的算子,只能通过groupByKey,先shuffle,有一个MapPartitionsRDD,然后用map算子,来处理每个key对应的values。就没有mapreduce的计算模型那么方便。
BlockManager原理剖析与源码分析
BlockManager原理剖析:

CacheManager原理剖析与源码分析
CacheManager原理剖析:

Checkpoint原理剖析
Checkpoint是什么?
Checkpoint,是Spark提供的一个比较高级的功能。有的时候啊,比如说,我们的Spark应用程序,特别的复杂,然后呢,从初始的RDD开始,到最后整个应用程序完成,有非常多的步骤,比如超过20个transformation操作。而且呢,整个应用运行的时间也特别长,比如通常要运行1~5个小时。
在上述情况下,就比较适合使用checkpoint功能。因为,对于特别复杂的Spark应用,有很高的风险,会出现某个要反复使用的RDD,因为节点的故障,虽然之前持久化过,但是还是导致数据丢失了。那么也就是说,出现失败的时候,没有容错机制,所以当后面的transformation操作,又要使用到该RDD时,就会发现数据丢失了(CacheManager),此时如果没有进行容错处理的话,那么可能就又要重新计算一次数据。
简而言之,针对上述情况,整个Spark应用程序的容错性很差。
Checkpoint的功能
所以,针对上述的复杂Spark应用的问题(没有容错机制的问题)。就可以使用checkponit功能。
checkpoint功能是什么意思?checkpoint就是说,对于一个复杂的RDD chain,我们如果担心中间某些关键的,在后面会反复几次使用的RDD,可能会因为节点的故障,导致持久化数据的丢失,那么就可以针对该RDD格外启动checkpoint机制,实现容错和高可用。
checkpoint,就是说,首先呢,要调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统的目录,比如说HDFS;然后,对RDD调用调用checkpoint()方法。之后,在RDD所处的job运行结束之后,会启动一个单独的job,来将checkpoint过的RDD的数据写入之前设置的文件系统,进行高可用、容错的类持久化操作。
那么此时,即使在后面使用RDD时,它的持久化的数据,不小心丢失了,但是还是可以从它的checkpoint文件中直接读取其数据,而不需要重新计算。(CacheManager)
Checkpoint原理剖析
1 | |
