介绍机器学习建模/数学建模的一般过程
目标定义
-
任务理解
-
指标确定
数据采集
-
建模抽样
-
质量把控
数据整理
- 数据探索
- 数据清洗
- 数据集成
- 数据变换
- 数据规约
构建模型
- 模式发现
- 构建模型
- 验证模型
模型评估
设定评估指标
回归任务的性能度量
-
绝对误差于相对误差
绝对误差:$E=Y-\hat{Y}$
相对误差:$e=\frac{Y-\hat{Y}}{Y}=\frac{Y-\hat{Y}}{Y}*100\%$
设$Y$为实际值,$\hat{Y}$为预测值
-
平均绝对误差 MAE
平均绝对误差(MAE,Mean Absolute Error),或被称为L1范数损失,作为评估指标来说现在用得比较少。
-
均方误差
均方误差(MSE,Mean Squared Error),是我们最常用的性能评估指标是
-
均方根误差
均方误差(RMSE,Root Mean Squared Error)
-
平均绝对百分误差
平均绝对百分误差(Mean Absolute Percentage Error, MAPE)定义如下
-
Kappa统计
Kappa统计比较的是对同一事物的两次或多次观测结果是否一致,以及由于机遇造成的一致性和实际观测的一致性之间的差异大小作为评价基础的统计指标。Kappa统计量和加权Kappa统计量不仅可以用于无序和有序分类变量资料的一致性、重现性检验,而且能给出一个反映一致性大小的“量”值。
Kappa取值在$[-1, +1]$之间,其值的大小均有不同意义。
- Kappa=+1说明两次判断的结果完全一致。
- Kappa=-1说明两次判断的结果完全不一致。
- Kappa=0说明两次判断的结果是机遇造成。
- Kappa<0说明一致程度比机遇造成的还差,两次检查结果很不一致,在实际应用中无意义。
- Kappa>0此时说明有意义,Kappa越大,说明一致性越好。
- Kappa>=0.75说明以经取得相当满意的一致程度。
- Kappa<0.4说明一致程度不够。
-
决定系数
因为MAE,MSE以及RMSE的局限性,在传统的线性回归中,我们往往会使用决定系数$R^2$对模型进行评估。
注意的是决定系数看上去似乎不再受到数据量级的局限,但是相比于MSE等指标,决定系数只能评估对线性模型的拟合程度,因此对于可能构建了非线性模型的算法来说(例如神经网络),我们还是需要使用RMSE进行评估。
分类任务的性能度量
- 准确率和错误率
对于分类任务来说,最常见的准确率和错误率。
模型的错误率:
模型的准确率:
其中 $I(f(x_i)=y_i)$为示性函数,但函数中内容为真时,函数结果取值为1,否则为0
- 查准率,查全率和F值
模型的准确率和错误率是最常用的指标,但是有时候仅仅使用模型的准确率和错误率并不足够。为了说明这一点,我们以二分类问题为例,假设我们建立了一个客户影响响应模型表示客户影响活动响应分析预测矩阵
| 预测值 | |||
|---|---|---|---|
| Positive | Negtive | ||
| 实际值 | Positive | TP | FN |
| Negtive | FP | TN |
对于模型评估,可以采取一些常用的指标进行判读。
模型准确率(Accuracy)
模型查准率(Precision)
模型查准率又被成为精确率。正如上面所说,我们更加关心此次营销活动中对客户的响应预测是什么样的情况,因此,这里引入模型精确率这个指标,它主要反映了我们对目标类别的预测准性。例如,建模人员提供了一份100人的客户响应名单,精确率研究的是在这份名单中有多少客户是真正响应营销活动的。
模型查全率(Recall)
模型查全率又被称为查全率。既然我们已经可以通过精确率把我们的焦点放在关注的类别上,那么分析工作是不是就可以结束呢?回到本案例中,假设又得到了一份100个用户响应名单,其中的精确率也非常高,有90人真正响应了营销活动,精确率达到90%。但问题是,如果最终响应情况是有1000人响应,那么我们就只是发现响应群体中的9%,很明显这个结果是不能接受的。因此,可以使用召回率这个指标来衡量我们是否能够将目标情况“一网打尽”。
需要值得注意的是,我们固然希望能够得到模型的查准率和查全率都比较高,但是模型的查全率和查准率往往是相互制约的,要提高查准率,往往会降低查全率,而要提高查全率则往往会降低查准率。而要综合考虑模型的查准率和查全率,我们可以借助P-R曲线。
如下图所示P-R曲线的纵坐标和横坐标分别是模型的查准率和查全率。要绘制P-R曲线,我们可以先对模型的预测样本按照准确率从高到低排序。接下来依次把判断阈值从高到低调整,之后按顺序阈值的调整顺序依次计算不同阈值的查准率和查全率,最后把计算结果绘制到图上就得到了下图的结果。事实上,随着阈值的逐渐降低,就是模型查准率下降而查全率上升的过程。
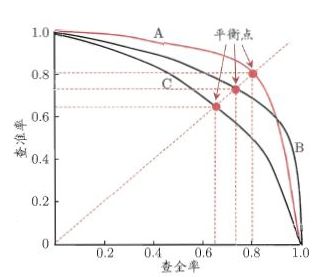
图 西瓜书中P-R曲线示意图
有一点需要值得注意的是,在实际的项目当中P-R曲线往往不会这么平滑,而且很有可能是取不到(0,1)以及(1,0)两个点。借助于P-R曲线,我们能够很好地对模型进行综合评估。当多个模型进行比较时,例如模型A的P-R曲线完全“包住”了另一个模型C的P-R曲线,则可以认为模型A的性能要优于模型C。但是当两个模型的P-R曲线发生交叉时,例如模型A和模型B的P-R曲线由于发生了交叉,则可能难以判断,这要根据我们实际的情形进行取舍。如果我们对模型的查准率有较高的要求,则可能选择模型A,而当我们对模型的查全率有较高的要求,则可能选择模型B。
不过另一角度来讲,如果本身我们对模型查准率和查全率没有明显的“偏好”,实际上我们其实可以使用曲线下面积作为取舍,曲线下面积越大,模型的综合性能越好。值得注意的是,作为对面积的替代,我们还可以利用“平衡点”(BEP,Break-Even Point),即产准率=查全率的取值点进行比较。在上图中,模型A的平衡点要高于模型B,因此我们可以认为模型A要优于模型B。
F Measure
某些情况下,只考虑平衡点可能过于简单,那么我们可以使用F1 Measure。
实际上F1值就是查准率和查全率的调和平均数,调和平均数常用于用在相同距离但速度不同时,平均速度的计算。一段路程,前半段时速60公里,后半段时速30公里(两段距离相等),则其平均速度为两者的调和平均数时速40公里。
但也正如我们前面所说的,有些场景下,我们对查准率和查全率的重视程度是不一样的。例如在体检过程中,我们希望尽可能发现体检者是否患有某种疾病,此时我们更加重视查全率。又例如在商品推荐中中,我往往不希望过于打扰客户,则会更加重视查准率。因此我们可以在F1值的计算中引入权重$\beta$,不妨使用$\beta$代表查全率相比查准率的重要性,有加权调和平均的计算如下:
显然当$\beta=1$时,就是$F_1$指标。
- ROC与AUC
通常,我们的算法模型也会为我们生成预测概率。一般我们可以选择一个阈值,当预测概率大于这个阈值时,我们将其划分为正类。通常我们习惯选取0.5作为阈值,当然,根据实际的任务需要,如果我们更加关注查准率,则可以适当调高阈值。相反,如果我们更加关注查全率,则可以适当调低阈值。
受试者工作特征曲线 (Receiver Operating Characteristic Curve,简称ROC曲线),与P-R曲线类似,我们根据预测概率对分类结果进行排序。之后从高到低依次选择阈值对样本进行分类,并计算出“真正例率”和“假正例率”。因为开始的时候,阈值最高,因此时所有的样本均被划分为负类,无论是“真正例率”和“假正例率”均为0。随着不断调低阈值,直至所有的样本均被划分为正类,这时无论是“真正例率”和“假正例率”均为1。真正例率(True Positive Rate , TPR)与假正例率(False Positive Rate , FPR)的定义如下:
一个典型的ROC曲线如下图所示,其中图上的对角线对应于随机猜测结果,曲线下面积越大,代表模型效果越好,显然如果模型A的ROC曲线完全包住另一个模型B的ROC曲线,我们可以说模型A的分类效果要优于模型B。最理想的模型是曲线直接去到(0,1)这个点,此时曲线下面积达到最大,为1。比较客观的比较方法同样可以使用面积,AUC曲线下的面积越大,说明模型的分类效果越好,我们把ROC曲线下的面积称之为AUC(Area Under ROC Curve)
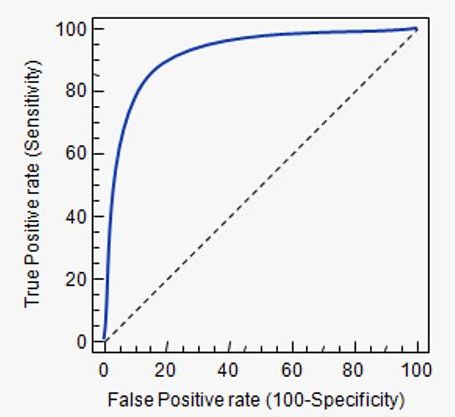
当然,因为在实际情况AUC(Area Under ROC Curve)是各点链接而成,一般出现不了上图这般平滑的曲线