背景介绍
由于项目中需要解析文本文件,初步打算用类似编译器(Lex+Bison)前端工具生成解析器目标Java代码,这类工具可以称为:”parser generators”。
经过阅读 Wikipedia Comparison of parser generators,对上面所列出工具的一番对比,发现 ANTLR4 可以满足要求;再深入对该工具了解,发现 ANTLR 官网的介绍:
ANTLR is a powerful parser generator that you can use to read, process, execute, or translate structured text or binary files. It’s widely used in academia and industry to build all sorts of languages, tools, and frameworks. Twitter search uses ANTLR for query parsing, with over 2 billion queries a day. The languages for Hive and Pig, the data warehouse and analysis systems for Hadoop, both use ANTLR. Lex Machina uses ANTLR for information extraction from legal texts. Oracle uses ANTLR within SQL Developer IDE and their migration tools. NetBeans IDE parses C++ with ANTLR. The HQL language in the Hibernate object-relational mapping framework is built with ANTLR.
文档 & 代码示例
ANTLR 4 Documentation 官方文档,介绍了如何编写grammer词法语法文件*.g4。grammer的g4文件,类似于扩展巴科斯范式(EBNF)
官方示例 Offical Code Examples 官方给的一些例子
“The Definitive ANTLR 4 Reference” 这本书是作者写的介绍如何用ANTLR4开发parser。书中包含的代码 A copy of code in “The Definitive ANTLR 4 Reference” for ANTLR 4.6
框架介绍
ANTLR4通过递归下降分析算法将grammer词法语法文件编译成目标代码文件,可以支持多种目标语言。
我们看下官方的一个简单的例子,这是一个赋值表达式的例子。语法这样写:
assign : ID '=' expr ';' ;
解析器的代码类似于下面这样:
1 | |
基本概念
语法分析器(parser)是用来识别语言的程序,本身包含两个部分:词法分析器(lexer)和语法分析器(parser)。词法分析阶段主要解决的关键词以及各种标识符,例如 INT、ID 等,语法分析主要是基于词法分析的结果,构造一颗语法分析树。大致的流程如下图所示。
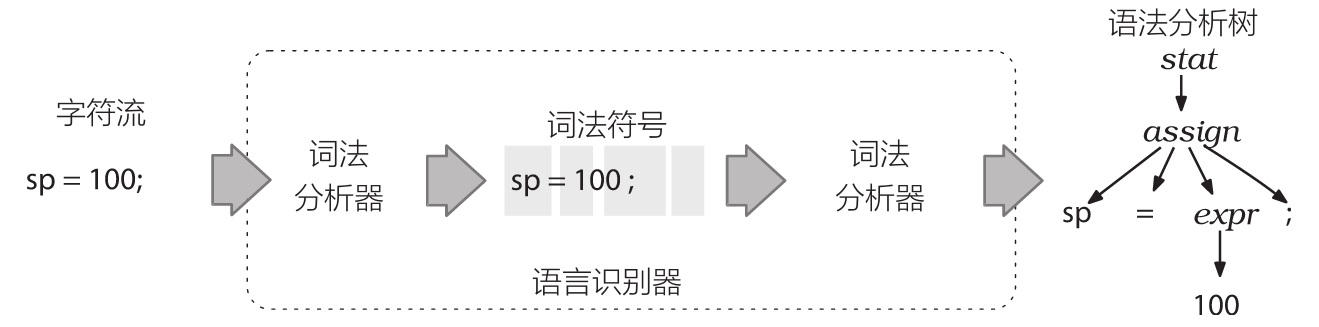
因此,为了让词法分析和语法分析能够正常工作,在使用 ANTLR4 的时候,需要定义语法(grammar)。
我们可以把字符流CharStream,转换成一棵ParseTree。CharStream是字符流,经过词法分析会变成Token流。 Token流再最终组装成一棵ParseTree,叶子节点是TerminalNode,非叶子节点是RuleNode.
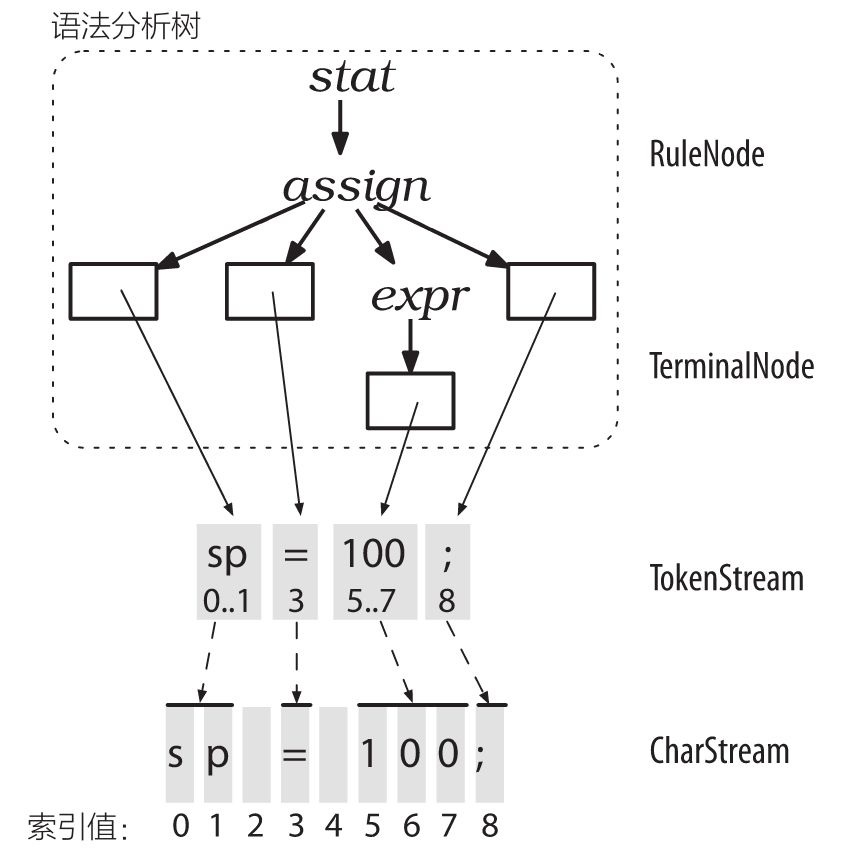
grammar语法
最重要的一点是,官方已经提供了非常多的常用的语言的语法文件了,可以删删改改直接拿来用: https://github.com/antlr/grammars-v4
grammar名称和文件名要一致- Parser 规则(即 non-terminal)以小写字母开始
- Lexer 规则(即 terminal)以大写字母开始
- 所有的 Lexer 规则无论写在哪里都会被重排到 Parser 规则之后
- 所有规则中若有冲突,先出现的规则优先匹配
- 用
'string'单引号引出字符串 |用于分隔两个产生式,(a|b)括号用于指定子产生式,?+*用法同正则表达式- 在产生式后面
# label可以给某条产生式命名,在生成的代码中即可根据标签分辨不同产生式 - 不需要指定开始符号
- 规则以分号终结
/* block comment */以及// line comment- 默认的左结合,可以用 `` 指定右结合
- 可以处理直接的左递归,不能处理间接的左递归
- 如果用
MUL: '*';指定了某个字符串的名字,在程序里面就能用这个名字了 - 用
fragment可以给 Lexer 规则中的公共部分命名
多种分支的情况
如果有多种可能的话,在语法里用|符号分别列出来就是了。ANTLR会把它翻译成switch case一样的语句。
我们把我们上面的例子扩展一下,不光支持=还支持:=赋值
grammar assign2;
assign : ID '=' expr ';'
| ID ':=' expr ';' ;
ID : [a-z]+ ;
expr : NUMBER ;
NUMBER : [1-9][0-9]*|[0]|([0-9]+[.][0-9]+) ;
生成的Parser就变成switch case了:
1 | |
二义性文法
选择太多了也未必见得是好事儿,有一种副作用就是选择不是唯一的,这叫做『二义性文法』。
最简单的二义性文法就是把同一条规则写两遍,比如上面例子的:=我们就改成=,让|之前和之后两条都一样。
grammar assign2;
assign : ID '=' expr ';'
| ID '=' expr ';' ;
ID : [a-z]+ ;
expr : NUMBER ;
NUMBER : [1-9][0-9]*|[0]|([0-9]+[.][0-9]+) ;
但是ANTLR4是兼容这种情况的,不报错。在实际应用的时候,它选择第一条符合条件的规则,请看生成的代码
1 | |
最著名的二义性的例子就是关键字。在常见的编程语言中,关键字都是和标识符冲突的. 比如我们定义一个if关键字:
IF : 'if' ;
ID : [a-z]+ ;
明显,IF和ID两个规则都可以解析’if’这个串,那到底是按IF算,还是按ID算呢?在ANTLR里,规则很简单,按照可以匹配的第一条处理。
但是,光靠第一条优先,也还是解决不了所有的问题。 我们看两类新的问题
第一类:1 + 2 * 3。这个如何处理,是先算+还是先算*?
前人想出了三种办法来解决:
- 从左到右:管人是如何理解乘除加减的,我就从左到右算。Smalltalk就是这样做的
- 中缀转前缀:带来问题的是中缀表达式,我们给换个形式不就OK了吗,比如改成这样
(+ 1 (* 2 3)),lisp就是这么做的 - 运算符优先级:最常用的一种作法,后面我们详情分析。基本上大部分常见的语言都有一个运算符优先级的表。
第二类,是一些语言的设计所导致的,给词法分析阶段带来困难。
比如”*“运算符,在大部分语言中都只表示乘法,但是在C语言中表示指针,当i*j时,表示乘法,但是当int *j;时,就变成表示指针。
ANTLR4 – Java Target Maven Example Project
以下以Java为目标语言用Maven构建一个例子工程Calculater
Maven工程构建
ANTLR4 提供了 Maven Plugin,可以通过配置来进行编译。
语法文件 g4 放置在 src/main/antlr4 目录下即可,配置依赖的 antlr4 和 plugin 即可。生成 visitor 在 plugin 配置 visitor 参数为 true 即可。
注意:ANTLR4 的库版本要与 plugin 版本对应,antlr4 对生成文件用的版本与库本身的版本会进行对照,不匹配会报错。
1 | |
grammar文件
简化版的calculator。参考:https://github.com/antlr/grammars-v4/tree/master/calculator/calculator.g4
grammar Calculator;
stmt: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: <assoc=right> expr op='^' expr # pow
| expr op=('*'|'/') expr # mulDiv
| expr op=('+'|'-') expr # addSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*';
DIV : '/';
ADD : '+';
SUB : '-';
ID : Letter LetterOrDigit*;
INT : Digit Digit*;
fragment Letter: [a-zA-Z_];
fragment Digit: [0-9];
fragment LetterOrDigit: Letter | Digit;
NEWLINE: '\r'? '\n';
WS: [ \t]+ -> skip;
在pom.xml中配置添加插件antlr4-maven-plugin,同时listerner和visitor配置为true,则生成以下代码文件。
等价于运行:alias antlr4="java -jar /path/to/antlr-4.5-complete.jar"
&& antlr4 -visitor Calculator.g4
1 | |
调用代码
1 | |
可以看到使用方法就是把输入流包装一下给 Lexer,之后将 Token 流给 Parser,最后调用 ParseTree:: 生成解析树。
解析树可以直接用 .toStringTree 按照 LISP 风格打印出来。
使用 Visitor 模式的话,就是新建 Visitor 对象,之后 visit(tree)。
使用 Listener 模式的话,需要一个 ParseTreeWalker 和一个 Listener 对象,然后用这个 walker 在树上用这个 Listener 行走。
不论是 Visitor 模式还是 Listener 模式,解决的痛点都是把结构和行为分开。
使用 ANTLR 4 中的 Visitor 模式
我们实现一个求值的 Visitor。
1 | |
通过上面的例子,可以看到, ANTLR 4 为每个产生式生成了对应的 visit 函数,并且有各自不同的 Context 对象 ctx。要访问子树需要使用 visit(ctx.());
ctx.()可以访问语法规则中的 `` 部分的 Contextctx.getText()可以获得在原文中的串
想知道 Context 对象里面有什么?当然,你可以看 Parser.java 里面写的。但是,如果你有一个带智能提示的 IDE 的话,那就非常舒服了!
使用 ANTLR 4 中的 Listener 模式
ANTLR 4 会为产生式生成
1 | |
这样的事件,类似 Visitor 模式按需填空即可。
传递参数与返回值
细心的读者应该注意到了,ANTLR 4 生成的 Visitor 模式中返回类型是统一的,而 Listener 模式直接就是 void ,并且两个模式都没有提供传入参数的地方。那么如果想要手动操纵返回值和参数怎么办呢?
ANTLR 4 Runtime 提供了一个 ParseTreeProperty ,其实大致就是个 IdentityHashMap。你可以把 Context 当作 key 把相关的东西丢进去。
Listener模式
还是前面的计算器,演示下 Listener 模式以及 ParseTreeProperty 的用法。
1 | |
Listener 模式与 Visitor 模式的比较
在 Visitor 模式中,树的遍历是需要我们自己手动控制的。这个有好处也有坏处。当你要实现一个树上的解释器的时候,用 Visitor 就很方便,比如你可以只执行 if-else 块中的一个,比如你可以重复执行循环语句的主体部分。当然坏处就是万一意外忘记遍历或者重复遍历就麻烦了。
在 Listener 模式中, walker 自顾自地走着,按顺序恰好遍历每个节点一次,进入或者退出一个节点的时候调用你的 Listener。因此,如果要实现一个树上解释器的话, Listener 模式就非常麻烦了。但是,如果想要构建一个 AST ,这种自动帮你一遍的事情就很舒服了。再比如要支持函数的后向调用,可以在第一次遍历中先把所有的函数名称找出来,然后再在第二遍遍历中做类型检查等等。
ANTLR4 testsuite
ACE Editor with ANTLR4
ACE.js是流行的前端页面编辑器,由JavaScript实现。可以结合ANTLR4实现自定义的语言关键字高亮等基本功能。
IntelliJ IDEA 插件支持
IntelliJ IDEA提供了 ANTLR 的插件用于调试语法文件*.g4。以Calculator中stmt这条Rule为例,右击该Rule选择”test Rule”,输入测试文本,即可出现下图所示解析树等信息:
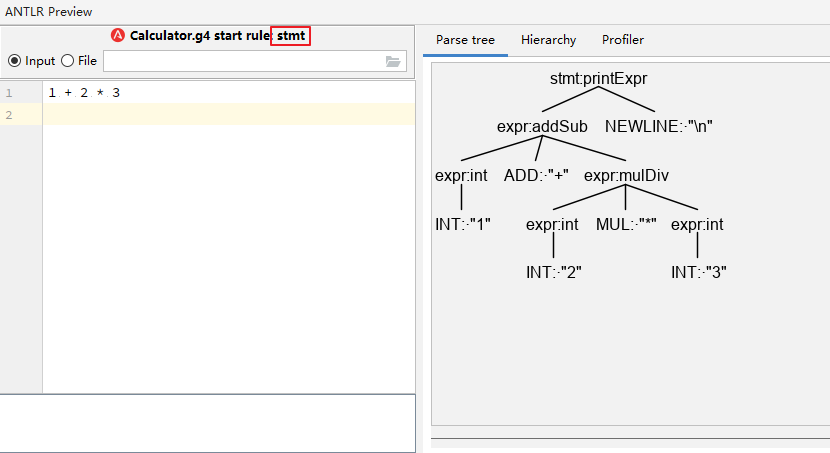
参考
- https://abcdabcd987.com/notes-on-antlr4/
- ANTLR快餐教程(2) - ANTLR其实很简单